- Industries
Industries
- Functions
Functions
- Insights
Insights
- Careers
Careers
- About Us


Data Extraction: Complex Tabular Form







Omega Consulting and Terra Edge Soft (TES) partnered to develop a high-performance data extraction engine tailored for one of the world’s leading Accounting, Auditing, and Taxation Advisory firms. The goal? To seamlessly extract mission-critical import/export data submitted to government authorities—embedded deep within digital PDFs containing multiple, intricately structured tables. The custom solution decisively outperformed leading commercial alternatives, addressing the unique demands of regulatory compliance, precision, and scale.
Background and Problem Statement
In today’s data-driven digital landscape, PDFs have become the universal standard for document exchange across industries—from finance and government to engineering and compliance. However, despite their widespread adoption, PDFs remain notoriously difficult to work with, especially when it comes to extracting structured data from complex tabular formats.
For one of our global clients—a prominent Accounting and Consulting firm—this challenge became critical. The organization regularly processes government-mandated declaration forms related to the import and export of materials. These documents, while digitally generated, contain intricate tables packed with regulatory data that must be accurately extracted, validated, and analyzed.
Standard PDF extraction tools, even those from leading providers, failed to deliver the required consistency and precision. Specifically, the client faced:
- Inconsistent Key-Value Pair recognition, leading to data loss or misclassification
- High dependency on manual intervention, increasing turnaround time and human error
- Ineffective handling of multi-layered tables, where nested structures and variable column spans confused traditional extraction logic
The inherent complexity of these PDFs—ranging from irregular table borders to merged cells and variable text alignments—rendered most off-the-shelf solutions inadequate. Even with advanced tools, accuracy degraded significantly, particularly in scenarios involving multiple tables across multiple pages or shifting data schemas.
The core issue was clear: the client required a solution that could intelligently parse, contextualize, and extract structured data from visually complex PDF tables—without sacrificing speed, scale, or accuracy.
Approach
To streamline extraction and reduce manual effort, Terra Edge Soft developed an AI-driven application tailored for complex tabular data in government-issued PDFs. The solution automates the parsing of multi-layered tables, ensuring accurate, fast, and cost-effective data extraction—significantly improving efficiency and reducing dependency on manual processing.
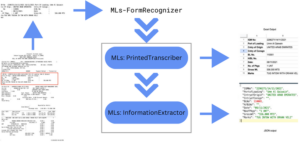
Our solution, MLs: Form Recognizer consists of two primary components:
MLs: Printed Transcriber is a customizable OCR engine designed to extract text, metadata, and structural elements from digital PDFs. It analyzes the positioning and layout of content across pages, enabling seamless parsing of complex document structures.
MLs: Information Extractor takes the transcribed data and converts it into structured formats like JSON or Excel. Tailored to specific document and table layouts, it ensures the accurate extraction of key data points for further analysis.
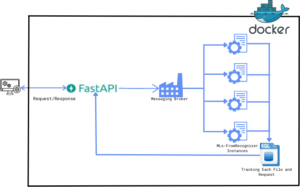
Solution Details
The solution is built as a containerized, Docker-based REST API that integrates multiple modules to provide a seamless, high-performance system. It ensures secure access and reliable PDF file uploads, while maintaining data integrity through robust processing mechanisms. To manage a high volume of requests efficiently, a queue-based approach is implemented, ensuring no requests are lost and output is delivered promptly.
A centralized database tracks and logs each interaction, enabling efficient monitoring, troubleshooting, and real-time issue resolution via email alerts. This system guarantees data consistency, minimizes downtime, and ensures fast, reliable results, all while providing a secure and efficient user experience.
Deployment
To provide the choice of access to the User, the following two options available:
- Hosted on a Clients’ server facility
- Hosted by us – Accessible via API
Typical Use Cases
- Financial Analysis: Extracts structured data from financial reports and filings for trend analysis, forecasting, and financial modeling.
- Market Research: Analyzes industry reports, surveys, and competitor data to gain insights into market size, growth, and consumer behavior.
- Healthcare & Medical Research: Extracts data from clinical trials, research papers, and patient records to support medical research, epidemiology, and decision-making.
- Government & Public Administration: Extracts data from reports and public records to aid policy development, data analysis, and evidence-based decisions.
- Manufacturing: Converts complex documents like bill of materials and cross-reference lists into actionable, structured data.
- Document Digitization & Archiving: Converts PDF documents into digital formats, enabling searchable databases, automated data entry, and long-term record preservation.
Benefits
- Improved Accuracy: Reduces manual errors with automated, consistent data extraction—maintaining an error rate under 1%. This ensures that businesses can rely on highly accurate data for decision-making processes.
- Increased Efficiency: Automates extraction, saving significant time and effort for data analysts. It also speeds up workflows, enabling teams to process more data in less time.
- Scalability: Handles large document volumes, enabling easy scaling of data processing operations. As businesses grow, the system adapts to meet expanding data extraction needs without compromising performance.
- Flexibility: Supports various table formats and can be customized for specific extraction needs. This adaptability ensures that even the most complex document layouts can be processed seamlessly.
- Cost Efficiency: Minimizes post-processing and reduces costs while managing large, complex files efficiently. With reduced manual intervention, organizations can optimize resources and improve their bottom line.
Overall, the table extraction application empowers data analysts to enhance productivity by streamlining workflows, extracting actionable insights, and enabling data-driven decision-making. It efficiently converts unstructured data into structured formats, improving the accuracy and speed of analysis.
Subscribe
Select topics and stay current with our latest insights
- Functions