- Industries
Industries
- Functions
Functions
- Insights
Insights
- Careers
Careers
- About Us


Big Data Privacy: Challenges and Solutions







Big Data refers to massive, complicated data sets that are beyond the capabilities of conventional data processing methods. These data sets are described by the “Three V’s”: volume (the sheer amount of data), velocity (the rapid rate at which data is generated and processed), and variety. Big Data sources include social media platforms, sensors, transaction records, and more.
Big Data’s relevance stems from its ability to reveal previously unreachable insights. Businesses can use sophisticated analytics to predict trends, provide personalized services, streamline processes, and make data-driven decisions. However, while Big Data has numerous potential, it also poses significant obstacles, the most important of which is data privacy. As data collecting expands, so will the risks of misuse, breaches, and the erosion of personal privacy, making it essential to address these concerns proactively.
Understanding Data Privacy in the Context of Big Data
Data privacy, at its core, is the right of individuals to control how their personal information is collected, used, and shared. In traditional data management systems, privacy concerns are typically addressed through direct consent and limited data access. However, in the context of Big Data, these concerns grow exponentially. This is due to the vast scale of data collection, the integration of various data sources, and the use of advanced analytics that can not only analyze existing data but also infer new, often sensitive, information about individuals
The sheer volume of personal data involved in Big Data can be staggering. Information is collected from a wide range of sources, including web browsing behaviors, social media interactions, transaction records, health data, location tracking, and even device usage patterns. Often, this data is collected without explicit consent or a full understanding from the individual of how it will be used. For example, combining data from a person’s social media activity with their online shopping history and geolocation data could reveal highly personal insights, such as preferences, lifestyle habits, and even health conditions—information that the individual may not have knowingly shared.
The potential for misuse—whether through data breaches, unauthorized sharing, or malicious exploitation—makes privacy protection a paramount concern in the Big Data landscape. Beyond the risks posed by bad actors, even well-intentioned organizations can inadvertently expose sensitive data due to weak privacy safeguards or improper data handling practices. Given the growing reliance on Big Data across industries, from marketing to healthcare, the urgency to address these privacy risks has never been greater. Strong data privacy protections are essential not only to maintain consumer trust but also to prevent serious harm to individuals whose data may be mishandled or exposed.
Key Privacy Risks in Big Data
Data Breaches and Unauthorized Access
Data breaches are among the most severe privacy concerns in the Big Data era. A breach happens when unauthorized individuals get access to sensitive information, typically through hacking or security flaws. In the context of Big Data, where vast datasets are stored and analyzed, a breach has a greater impact. A single breach can expose millions of people’s personal and financial information, resulting in serious implications like identity theft, financial fraud, and long-term reputational harm for both the individuals impacted and the companies responsible.
Big Data systems’ dispersed design increases the risk of unwanted access. Data is frequently stored on many servers, cloud environments, and even physical locations. This shared storage increases the number of points of risk because data is accessible and processed by a wide range of stakeholders, including workers and external vendors. If just one access point is compromised, the entire data network may be jeopardized. Furthermore, weak security processes, the usage of obsolete or unpatched software, and insider threats (in which individuals within an organization purposefully or accidentally reveal sensitive data) all increase the likelihood of a breach.
Breaches can occur as a result of basic human error, such as misconfigured databases or the unintended sharing of sensitive files, but the consequences are the same. As Big Data systems become more complicated and scaled, implementing strong security measures such as encryption, multi-factor authentication, and frequent security audits is crucial to reducing the risk of data breaches and safeguarding user privacy.
Re-identification and De-anonymization Risks
Anonymization is a frequently used technique for preserving privacy by removing personally identifiable information (PII) from datasets. Organizations try to decrease the danger of disclosing individuals’ identities by removing direct identifiers like names, addresses, and Social Security numbers from data. However, the effectiveness of anonymization in Big Data contexts is being called into doubt as the risk of re-identification grows.
The process of re-identification involves cross-referencing anonymized data with other datasets to re-identify individuals. This issue is more apparent with Big Data because of the massive number and variety of available information. With so many data sources—from social media activity and transaction records to location data and public databases—it is now possible to associate supposedly anonymous data points with additional identities. Even if names and addresses have been deleted from a data source, indirect identifiers such as ZIP codes, gender, or birth dates may remain. Individuals’ privacy can be jeopardized when this information is combined with publicly available records or additional data sets.
The potential of de-anonymization increases as more data sets become available, particularly in industries such as healthcare, retail, and finance, where highly comprehensive information is frequently collected. According to studies, up to 87% of individuals in an anonymised data set can be re-identified using only a few characteristics, such as ZIP code, birth date, and gender. This indicates that even well-intentioned anonymization efforts may not be enough to ensure privacy, especially when powerful algorithms and machine learning techniques are employed to reconstruct fragmented data.
Inference Attacks and Predictive Analytics
Inference attacks occur when an attacker employs statistical techniques to deduce sensitive information that is not directly accessible in the data. Predictive analytics in Big Data, which uses data patterns to forecast actions or trends, might unintentionally reveal personal information about individuals.
For example, a corporation studying a customer’s purchase history may infer personal information such as health issues or financial difficulties. If such inferences are leaked or exploited, they can result in negative repercussions such as discrimination, stigmatization, or invasion of privacy. The misuse of predictive analytics emphasizes the delicate balance between useful insights and the risk of invading personal privacy.
Data Aggregation and Profiling Concerns
Data aggregation is the process of collecting information from multiple sources to create detailed profiles of persons. This method is increasingly widespread in marketing, where corporations collect data from a variety of sources—including social network activity, purchase history, browsing behavior, and even public records—to provide highly tailored advertisements. While this type of customisation can improve marketing efforts and user experience, it also raises serious privacy concerns.
Aggregated profiles frequently include sensitive personal information that individuals may not have agreed to reveal in a larger context, such as political affiliations, sexual orientation, health status, or financial data. When this information is combined, it forms a thorough picture of a person’s life that can be utilized for purposes other than marketing. The concerns include discriminatory practices, in which people are targeted or excluded based on aggregated data, as well as the possibility of manipulating behavior through highly particular and disruptive advertising. In more serious circumstances, this information could be utilized by criminals for fraud, identity theft, or mass surveillance, violating an individual’s right to privacy and autonomy.
As data aggregation grows, especially with the advancement of artificial intelligence and Big Data technologies, the risks of misuse increase. Aggregated data profiles constitute a substantial threat to personal privacy in the absence of robust legislation and open processes, highlighting the need for greater data governance, informed permission, and improved privacy safeguards to protect individuals from exploitation.
Surveillance and Tracking Issues
One of the most concerning privacy issues in Big Data is the potential to track people’s activities and actions across numerous platforms and devices. This type of surveillance can be carried out by governments, companies, or criminal actors, frequently without the subjects’ explicit awareness or agreement.
Continuous tracking allows for the production of detailed records of a person’s daily activities, such as their location, social interactions, browsing patterns, and preferences. This widespread surveillance not only jeopardizes personal privacy but also has a substantial impact on an individual’s sense of freedom and autonomy. The constant feeling of being watched and scrutinized can inhibit people from freely expressing themselves or engaging in particular activities.
Furthermore, the information gathered through monitoring can be utilized for a variety of objectives, including targeted advertising, behavioral manipulation, and even government surveillance. This intensive monitoring raises severe ethical concerns regarding the loss of human liberties and the potential misappropriation of sensitive data.
As technology progresses, the ability for tracking and monitoring expands, making it critical to implement strong privacy safeguards and maintain openness in data gathering procedures. Effective restrictions and protections are required to protect individuals from unjustified intrusions into their private lives and to preserve their autonomy in a data-driven future.
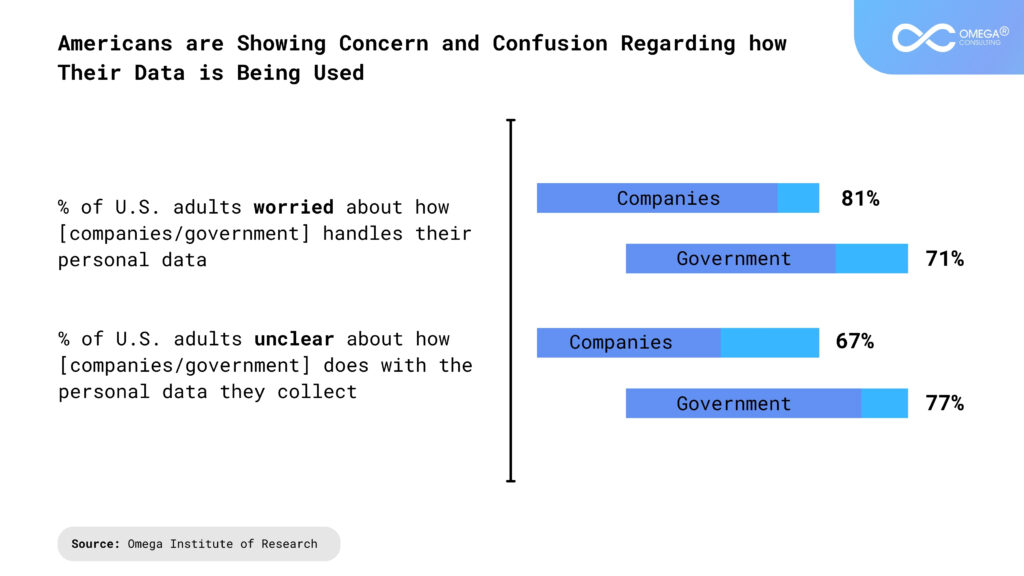
What’s Fueling Privacy Risks in the Age of Big Data
Volume, Velocity, and Variety of Data (The Three V’s)
The three V’s—Volume, Velocity, and Variety—are defining characteristics of Big Data that also contribute to privacy risks:
Volume: The huge amount of data collected poses significant issues for administration and security. Large databases are difficult to monitor completely, increasing the probability that privacy violations may go undiscovered. The impact of a breach is significantly compounded, as corrupting vast datasets might harm millions of individuals at once.
Velocity: Data is produced and processed at unprecedented rates, frequently in real time. Because of this rapid pace, companies may mistakenly disregard privacy protections in favor of immediate analysis and response. To ensure that privacy protections keep up with the speed of data processing, continual monitoring and strong safeguards are required to prevent illegal access and misuse.
Variety: The variety of data types—from text and images to videos complicates privacy protection. Different data types may have distinct privacy requirements, and merging them can result in unexpected hazards. For example, combining location data and social media activity can result in more specific and intrusive insights than each data type alone.

Data Sharing Practices and Third-Party Risks
Organizations often share data with third parties, such as vendors, partners, and service providers. Each time data is shared, it introduces new privacy risks.
- Privacy Standards: When data is transferred to third parties, there is a risk that the external entities will not follow the same strict privacy standards as the original data collector. Differences in privacy standards might create risks, exposing sensitive data to breaches or unauthorized access.
- Data Sharing Agreements: Data-sharing agreements frequently lack clear, comprehensive language outlining each party’s duties for data security. This confusion can lead to insufficient data protection, with unclear rules for handling, storing, and securing information. As a result, data may be misused, resulting in privacy issues.
- Jurisdictional Variability: The location of third parties may complicate privacy protection. Data shared with entities in various jurisdictions may be subject to varying privacy standards, some of which may be more relaxed than those governing the original data collector’s location. This can lead to weaknesses in data protection and an increased risk of misuse or exploitation.
Inadequate Anonymization and Pseudonymization Techniques
Anonymization and pseudonymization are popular approaches for protecting privacy by eliminating or changing personally identifying information (PII). Despite their advantages, these solutions are not perfect and can often fall short in protecting data from privacy threats.
Anonymization: This technique removes or obscures direct identifiers from datasets to prevent individuals from being identified. However, as we previously mentioned insufficient anonymization may leave data vulnerable to re-identification. As data sets grow in complexity and are integrated with other information, patterns and unique identities may develop, allowing data to be traced back to individuals. For example, integrating anonymized data with publicly available records or supplementary datasets can re-identify people, jeopardizing their privacy.
Pseudonymization involves replacing personal identifiers with false identities, so eliminating the direct link to human identities. While this strategy improves privacy, it does not completely eliminate risk. Individual privacy may be jeopardized if pseudonymized material is reconnected to its original identifiers—whether through data breaches, insufficient pseudonymization mechanisms, or reverse engineering. The efficiency of pseudonymization is determined by the strength of the method used and the security with which the pseudonyms are administered.
Organizations have to deal with the limitations of both anonymity and pseudonymization. In the context of Big Data, where massive amounts of information are processed and cross-referenced, even minor flaws in these methodologies might result in severe privacy violations. For instance, advanced algorithms and data integration methods can occasionally bypass these safeguards, disclosing sensitive information.
Insufficient Security Measures and Protocols
Effective security is critical for protecting Big Data platforms, yet many organizations struggle with insufficient measures.
- Outdated Software: Failure to update software exposes systems to known vulnerabilities, which hackers can exploit. Regular updates and fixes are critical for security.
- Weak Encryption: Poor encryption methods can expose data to unauthorized access. Strong, up-to-date encryption standards are required to protect data.
- Lack of Security Assessments: Without frequent security assessments, vulnerabilities may go unnoticed. Routine audits and vulnerability scans are crucial for detecting and mitigating hazards.
- Inadequate Incident Response: Poorly specified or out-of-date incident response strategies can cause delays or exacerbate the handling of breaches. A well-developed and proven plan is essential for successful response and damage management.
- Unauthorized Access: Insufficient access controls can result in unauthorized data access. Implementing strong role-based access controls and multi-factor authentication can help protect sensitive information.
Without robust security protocols, data can be accessed, altered, or stolen by unauthorized individuals, leading to significant privacy violations. Ensuring that security measures are regularly updated and tested is critical to mitigating these risks.
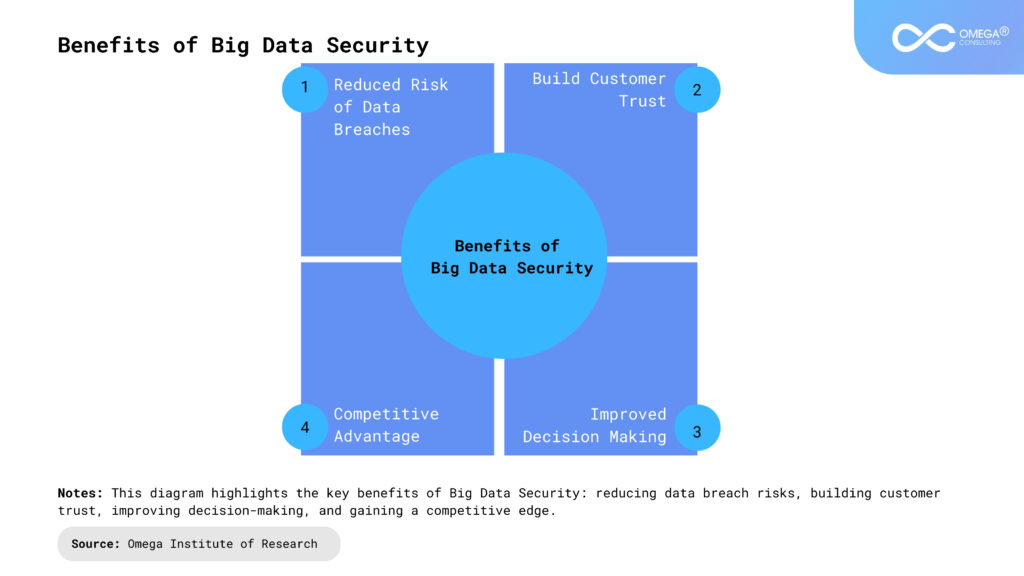
Securing Big Data: The Benefits
Big data security enables organizations to unlock the full potential of their data, minimizing risks, building trust, and fueling growth and innovation. Let’s explore the key advantages of implementing robust big data security measures.
Reduced risk of data breaches
Big data security plays a crucial role in reducing the risk of data breaches by implementing various measures to protect data confidentiality, integrity, and availability. Implementing measures like role-based access control, data encryption, threat detection, and real-time monitoring significantly reduces the risk of data breaches. Big Data protection solutions also use firewalls, intrusion detection systems (IDS) and intrusion prevention systems (IPS), which can monitor the network and detect and block suspicious activities, reducing the risk of data breaches.
Increased customer trust
In today’s digital world, data security is critical to building customer trust. With rampant incidents of data breaches, customers are increasingly concerned about how businesses handle their personal and sensitive data. According to Statista, only 46% of U.S. customers trusted their banks and financial institutions to protect their data. This data shows there is a trust deficit among customers and businesses when it comes to data privacy and security.
Big data security helps in protecting customer data from unauthorized access. When customers see that a company protects their data and privacy, they are more likely to trust the company and remain loyal to it. Many organizations employ reputed third parties for security audits, validating the company’s data security commitment and reassuring customers that their data is safe.
Improved decision-making
Big data security helps maintain data integrity and accuracy by protecting it from unauthorized access. Security measures like encryption, restricted access, and authentication ensure that only authorized individuals can access sensitive information. A secure data environment helps identify accurate insights and patterns, assisting stakeholders in making the right and data-driven decisions. For example, banks can use big data to improve their risk management and fraud detection capabilities and offer loans to customers with good credit history. However, this is possible only when the data is secure and correct.
Competitive advantage
Big data security offers businesses a competitive advantage by safeguarding critical assets and helping them make decisions based on data. protecting customers’ data and ensuring privacy, companies can enhance trust and loyalty, ultimately boosting customer retention. Businesses with robust security measures also attract partners who can help in business growth. These factors contribute to the company’s growth and help companies outpace competitors yet to invest in big data security analytics.
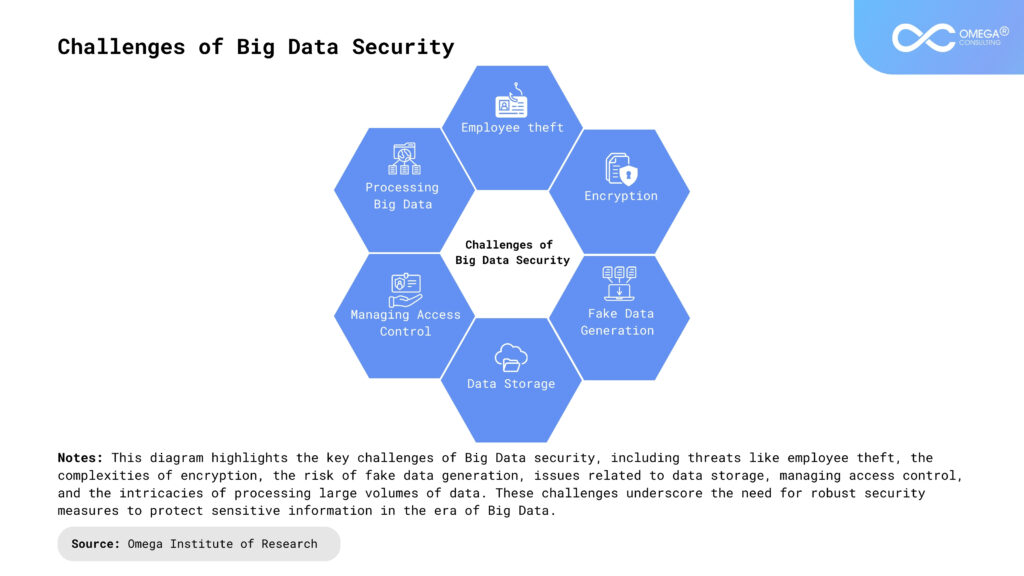
Common big data security challenges
Securing big data is a significant challenge in today’s digital landscape as attackers use sophisticated technologies and innovative methods, making it essential for businesses to understand big data security challenges.
Let’s look at the top big data security challenges that will help you take appropriate measures to secure your data.
Data storage
Big data involves storing and processing vast amounts of data; securing it can be challenging. Big data systems store various data types, including unstructured, structured, and semi-structured data, making it difficult to implement security measures effectively across all data types. Moreover, data redundancy and replication are common in big data architecture, meaning that sensitive data may exist in multiple locations, which increases the risk of unauthorized access.
Data privacy
Data privacy is a significant challenge for big data security because big data systems often collect and store large amounts of personal data. It collects data from multiple sources, including online and offline activities, making it difficult for businesses to secure and maintain data privacy. Furthermore, big data systems involve sharing data with third-party applications and services that can increase the risk of data breaches and unauthorized access.
Fake data generation
Fake data generation is another big data security challenge because it can be used to manipulate and deceive big data systems. This challenge can lead to inaccurate results and insights, forcing businesses to make wrong decisions. For example, criminals may generate fake product reviews to manipulate potential customers’ purchase decisions. Besides that, fake data can be used to mask real data, making it easier for attackers to steal sensitive data.
Managing access control
Big data systems are highly complex and distributed, spreading data across multiple storage locations and servers. This makes it difficult to implement and manage access controls that can work for all data formats. Big data systems also store large volumes of data and share them with third-party applications and services. Managing access to such massive and diversified data is a major challenge, and the risk of unauthorized access to the data is always higher.
Processing big data
Big data means complex and distributed data across multiple systems, and processing it involves significant risk as the data is exposed to various third-party software and servers. Data is generated and processed rapidly in a big data system, often in real-time. This high velocity makes it difficult to monitor and respond to security threats in a timely manner. As the volume grows, processing the data while ensuring security measures requires careful planning and implementation of robust security practices.
Employee theft
Every employee in an organization has some amount of access to the data, especially those who are involved in big data analysis. Some employees even have insider knowledge of the organization’s data systems, including access controls, passwords, and security protocols. An employee with access to a big data system can exploit the authority to gain unauthorized access to sensitive data. They can also manipulate data to cause financial and reputational harm to the organization.
Legal and Ethical Considerations
Overview of Data Protection Regulations (GDPR, CCPA, etc.)
Data protection regulations, such as the General Data Protection Regulation (GDPR) in the European Union and the California Consumer Privacy Act (CCPA) in the United States, set standards for how organizations must handle personal data. These regulations aim to protect individuals’ privacy rights by imposing strict requirements on data collection, processing, and storage.
Key aspects of these regulations include:
- Consent: Organizations must secure explicit consent from individuals before collecting or processing their data. Consent must be informed, specific, and freely given, ensuring that individuals understand what their data will be used for.
- Data Subject Rights: Individuals are granted various rights regarding their data, including the right to access, correct, and request deletion of their personal information. These rights empower individuals to control their data and ensure its accuracy.
- Data Breach Notification: In the event of a data breach, organizations are required to promptly notify affected individuals and relevant authorities. Timely notification is crucial for mitigating potential harm and ensuring transparency.
- Accountability: Organizations must demonstrate compliance with data protection regulations through documentation and evidence. This includes maintaining records of data processing activities and implementing appropriate security measures.
Ethical Implications of Data Collection and Usage
Beyond legal compliance, corporations must face ethical considerations while handling Big Data. Ethical data practices include:
- Respecting Privacy: Organizations should prioritize individuals’ privacy by ensuring that data gathering and use do not violate personal privacy. Even with consent, data practices must be carried out with respect and care.
- Transparency: Communicating openly about data collecting techniques, usage aims, and sharing policies fosters confidence. Organizations should explain clearly about how data is gathered, used, and protected.
- Avoiding Harm: Data should not be utilized unethically or discriminatorily. For example, using data to exploit vulnerabilities or unjustly target specific groups can be both destructive and unethical.
Organizations must weigh the benefits of data analysis against potential hazards to individuals and society, ensuring that their practices align with ethical standards and promote fairness and respect.
For example, even if legally permissible, using data to manipulate individuals’ behavior or to discriminate against certain groups can be ethically problematic. Organizations must weigh the potential benefits of data analysis against the potential harm to individuals and society.
Compliance Challenges for Organizations
Navigating data protection legislation poses various obstacles, particularly for firms operating across multiple nations.
- Varying Regulations: Different countries have different privacy regulations, and complying with each can be resource-intensive. Organizations must constantly change their practices to comply with different and changing rules.
- Supply Chain Compliance: Ensuring that all partners and third-party vendors follow data protection standards is critical. This includes comprehensive verification, explicit contractual requirements, and continual monitoring to assure supply chain compliance.
- Resource Allocation: Implementing and sustaining compliance necessitates significant investment in legal expertise, technology, and training. Organizations must provide adequate resources to successfully manage compliance and mitigate risks.
Addressing these compliance issues is critical to preserving data integrity, protecting privacy, and avoiding legal and reputational penalties.
Strategies to Mitigate Privacy Risks
Implementing Data Minimization Principles
Data reduction refers to gathering only the information required for particular goals. Organizations can lower their risk of privacy breaches and streamline data management by restricting the amount of data they collect. For example, gathering additional information such as physical addresses or phone numbers may be unnecessary if a business only requires a customer’s email address to issue receipts. Using data minimization techniques improves privacy protection and complies with numerous data protection laws, including the CCPA and GDPR.
Effective Anonymization and Pseudonymization Techniques
Anonymization and pseudonymization are essential for safeguarding privacy in Big Data environments. Both techniques help to protect individual identities and ensure compliance with data protection regulations.
- Anonymization: This method entails converting data so that, even when paired with information from other sources, people cannot be identified again. Among the efficient techniques for anonymization are:
- Data Masking: The process of substituting fictitious or scrambled values for sensitive data items. For example, generic placeholders may be used in place of genuine names.
- K-Anonymity: ensures that each record in a dataset is indistinguishable from at least ‘k-1’ other records by generalizing or masking personal information. For example, instead of showing exact ages, ages might be grouped into ranges, making it difficult to identify a specific individual.
- Differential Privacy: The process of obscuring individual identities in data while preserving the ability to conduct insightful analysis. Regardless of the size of the dataset or the quantity of auxiliary information provided, differential privacy guarantees that the danger of identifying specific persons is negligible.
- Pseudonymization: This tactic, which can be reversed under certain circumstances, entails substituting pseudonyms for personal identification numbers. By separating data from direct identifiers yet preserving the ability to analyze the data, it offers an additional degree of privacy protection. Important elements consist of:
- Data replacement: Pseudonyms or tokens are used in place of identifiable information, such as social security numbers or names. For instance, a distinct code might be used in place of the patient’s name.
- Controlled Re-Identification: Only individuals with the necessary authorization and access to the key or re-identification algorithm are able to view the original data. When data needs to be re-linked to original identities for particular studies while retaining overall privacy, such as in medical research, this is helpful.
Encryption and Robust Security Protocols
Data security must be protected by encryption. It converts data into a format that is unreadable so that without the proper decryption key, unauthorized people cannot access or understand it. To properly protect sensitive information, organizations should encrypt both data in transit (data being exchanged) and data at rest (data being maintained).
It’s critical to employ strong security mechanisms in addition to encryption:
- Frequent Security Assessments and Updates: To handle new and developing threats, regularly assess and update security measures. Frequent evaluations guarantee that protections continue to be effective and assist in identifying vulnerabilities.
- Incident Response Plans: Create and uphold explicit protocols for handling data breaches, including notification, investigation, and containment. Rapid security restoration and damage mitigation are made possible by effective event response.
- Network Segmentation: To prevent breaches from spreading and to limit access to critical data, divide the network into smaller, controlled portions. By limiting exposure and containing possible threats, network segmentation improves security.
Access Controls, Authentication, and Authorization
Access controls are essential for limiting authorized personnel’s access to data. By implementing role-based access controls (RBAC), employers can lower the risk of unauthorized data disclosure by ensuring that workers can only access the data required for their particular job activities.
By demanding several kinds of verification before giving access, authentication systems like multi-factor authentication (MFA) improve security. This extra security measure guarantees that systems and data are only accessible to authorized users.
In order to manage permissions and make sure that only authorized users have the ability to access and alter data in accordance with their allowed rights, authorization processes are crucial. Permission that is effective keeps people from accessing or changing data outside of their designated roles.
Ensuring Transparency and Obtaining Consent
Building trust and making sure people understand how their data is used require transparent data practices. Companies should have easily readable privacy rules that explain what information is gathered, why it is collected, and who else may receive it. People may make more educated judgments about their data thanks to this transparency.
It is both ethically and legally required to obtain informed consent. People must be informed of the implications of their choices and given the option to opt in or out of data collection. Respecting people’s autonomy and right to privacy means making sure consent is acquired in an open and transparent manner.
Regular Audits, Monitoring, and Compliance Checks
For the purpose of detecting and mitigating privacy concerns prior to breaches, routine audits are essential. These audits should examine compliance to legal requirements, evaluate the efficiency of security precautions, and identify any potential weak points.
Continued Monitoring data access and usage helps spot suspicious actions in real time, enabling quick action to resolve any breaches. This proactive strategy improves data security in general.
Compliance checks make sure the company keeps its privacy policies up to date and complies with legal obligations. Frequent audits assist in ensuring that the company consistently complies with its ethical and regulatory requirements.
Case Studies
Facebook-Cambridge Analytica Scandal
Background
In 2018, the world learned of a massive data privacy breach involving Facebook and a political consulting firm, Cambridge Analytica. The firm had harvested the personal data of millions of Facebook users without their consent and used this data to influence political campaigns, including the 2016 U.S. Presidential election and the Brexit referendum in the UK.
Privacy Risks
- Unauthorized Data Collection: Cambridge Analytica accessed Facebook users’ data through a third-party app that ostensibly collected data for academic research. However, the app not only collected data from users who installed it but also harvested data from their friends without consent.
- Data Exploitation for Manipulation: The data was used to create detailed psychological profiles, which were then employed to target voters with personalized political advertisements designed to influence their behavior.
- Lack of Transparency and User Control: Facebook users were unaware that their data was being collected and used for purposes beyond what they had consented to. There was no transparency regarding how their data was being utilized.
Consequences
The scandal led to widespread outrage, multiple government investigations, and significant damage to Facebook’s reputation. It also resulted in a $5 billion fine for Facebook by the U.S. Federal Trade Commission (FTC), one of the largest fines ever imposed for privacy violations.
How to Avoid Such Risks
- Implement Strict Data Access Controls: Companies should ensure that third-party apps or partners have limited access to user data and that such access is strictly monitored. Only essential data should be shared, and user consent should be mandatory.
- Enhance Transparency and Obtain Informed Consent: Users must be clearly informed about how their data will be used and should provide explicit consent for all data collection and processing activities.
- Regular Audits and Compliance Checks: Organizations should conduct regular audits of third-party applications and partners to ensure they comply with privacy policies and regulations.
- Invest in Privacy by Design: By embedding privacy considerations into the design of systems and services, companies can prevent misuse of data and ensure that user privacy is protected from the outset.
Equifax Data Breach
Background
In 2017, Equifax, one of the largest credit reporting agencies in the world, suffered a data breach that exposed the personal information of approximately 147 million people, including Social Security numbers, birth dates, addresses, and in some cases, driver’s license numbers.
Privacy Risks
- Failure to Patch Known Vulnerabilities: The breach occurred because Equifax failed to address a known vulnerability in one of its web applications. Despite being aware of the vulnerability, the company did not take timely action to secure its systems.
- Inadequate Security Measures: Equifax’s security practices were insufficient to protect sensitive data. The company did not employ robust encryption for all sensitive data, and there were weaknesses in its incident detection and response processes.
- Extended Exposure: The breach went undetected for more than two months, during which time attackers were able to continuously access sensitive information.
Consequences
The breach led to massive public backlash, multiple lawsuits, and significant financial losses for Equifax. The company agreed to a settlement of up to $700 million with the Federal Trade Commission (FTC), the Consumer Financial Protection Bureau (CFPB), and 50 U.S. states and territories.
How to Avoid Such Risks
- Regular Security Patching and Updates: Organizations must prioritize the patching of known vulnerabilities in their systems. Regular updates and maintenance are critical to protecting sensitive data from emerging threats.
- Strengthen Data Encryption: Sensitive data should be encrypted both at rest and in transit to prevent unauthorized access in the event of a breach.
- Implement Stronger Incident Response Plans: Organizations should have robust incident detection and response plans in place to quickly identify and mitigate breaches. Regular drills and updates to these plans can ensure preparedness.
- Conduct Continuous Security Audits: Regular security audits and penetration testing can help identify vulnerabilities before attackers do. These audits should be conducted by both internal teams and independent external parties.
Future of Big Data Privacy: Emerging Trends and Innovations
Impact of Emerging Technologies (AI, Machine Learning) on Privacy
Emerging technologies such as artificial intelligence (AI) and machine learning (ML) are transforming the way data is analyzed and used. However, these technologies also introduce new privacy risks. For example, AI algorithms can infer sensitive information from seemingly innocuous data, while ML models trained on biased data can perpetuate discrimination.
As AI and ML become more prevalent, organizations must ensure these technologies are used ethically and transparently. This includes assessing the privacy implications of AI systems, implementing safeguards to prevent misuse, and regularly auditing AI models for bias and fairness.
Evolution of Data Protection Regulations
Data protection regulations are constantly evolving to address new privacy challenges. The introduction of the GDPR and CCPA has set a high standard for data protection, but new regulations are emerging in other regions as well. For example, the Personal Data Protection Bill in India and the Lei Geral de Proteção de Dados (LGPD) in Brazil are shaping global privacy standards.
Organizations must stay informed about changes in data protection laws and be prepared to adapt their practices accordingly. This requires ongoing monitoring of regulatory developments, as well as collaboration with legal experts to ensure compliance.
Advances in Privacy-Enhancing Technologies (PETs)
Privacy-enhancing technologies (PETs) are tools and techniques designed to protect data privacy while enabling data analysis and sharing. Some of the most promising PETs include:
- Homomorphic encryption: Allows data to be processed without being decrypted, ensuring that sensitive information remains protected even during analysis.
- Secure multi-party computation (SMPC): Enables multiple parties to jointly compute a function over their inputs while keeping those inputs private.
- Differential privacy: Adds noise to data to prevent the identification of individuals, allowing for the analysis of trends without compromising privacy.
As these technologies advance, they offer new opportunities for organizations to leverage Big Data while maintaining strong privacy protections.
Conclusion
Balancing the benefits of Big Data with the need to protect individual privacy is a complex but essential task. Organizations must adopt a holistic approach that includes robust security measures, compliance with legal standards, and a commitment to ethical data practices. By prioritizing privacy, organizations can build trust with customers, avoid costly breaches, and unlock the full potential of Big Data in a responsible and sustainable manner.
Moving forward, the landscape of Big Data privacy will continue to evolve, driven by technological advancements, regulatory changes, and shifting societal expectations. Organizations that stay ahead of these trends and invest in privacy protection will be well-positioned to thrive in the data-driven economy.
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7660312/
- https://maddevs.io/blog/big-data-security-best-practices/
- https://www.turing.com/resources/big-data-security
- https://maddevs.io/blog/big-data-security-best-practices/
- https://careerfoundry.com/en/blog/data-analytics/is-big-data-dangerous/
- https://www.scarlettculture.com/big-data-privacy-concerns
- https://www.pewresearch.org/internet/2023/10/18/how-americans-view-data-privacy/
Subscribe
Select topics and stay current with our latest insights
- Functions