- Industries
Industries
- Functions
Functions
- Insights
Insights
- Careers
Careers
- About Us


Training, Validation, and Test Data Sets







In machine learning, the way you divide and utilize data plays a critical role in determining your model’s success. Training, validation, and test data sets each serve unique purposes that collectively ensure your model is accurate, robust, and capable of generalizing to unseen scenarios. The training set is the foundation, used to teach the model by identifying patterns in the data. The validation set is instrumental in fine-tuning hyperparameters and preventing overfitting, ensuring the model performs well on new inputs. Finally, the test set acts as the ultimate benchmark, evaluating the model’s performance on entirely unseen data. By understanding the distinct roles of these data sets and adhering to best practices for their allocation and usage, you can build machine learning models that are not only high-performing but also reliable in real-world applications. Mastering this process is a cornerstone of achieving excellence in machine learning.
Training Data: The Core of Learning
Volume: The size of the training dataset influences the model’s ability to learn and generalize patterns. Larger datasets allow the model to capture a broader range of relationships, making it more capable of handling complex scenarios. However, increasing dataset size without ensuring relevance can lead to inefficiencies, such as longer training times and unnecessary computational costs. Including redundant or irrelevant data may introduce noise, hindering performance instead of improving it.
Diversity: A diverse training dataset ensures the model generalizes well to various situations and avoids biased predictions. Diversity exposes the model to a wide range of scenarios, making it more reliable in real-world applications. For instance, in speech recognition, including audio samples from speakers with different accents and genders prevents demographic bias. Without such diversity, the model may perform inconsistently across different user groups.
Quality: High-quality data ensures the model learns accurate patterns, improving performance and generalization. Noisy data, such as mislabeled examples or outliers, can mislead the model and degrade accuracy. Data preprocessing techniques like cleaning, normalization, and augmentation are essential to enhance dataset reliability. Removing duplicates and correcting labels significantly improves the model’s robustness while reducing the need for post-training adjustments.
Challenges in Training Data
- Imbalanced Classes: Imbalanced datasets, where one class significantly outweighs others, can cause the model to favor the dominant class, leading to biased predictions. For example, in medical diagnosis, a dataset with far more negative cases than positive ones may result in a model that struggles to identify rare diseases. Addressing this issue requires strategies like oversampling the minority class, undersampling the majority class, or using advanced techniques like synthetic data generation or weighted loss functions.
- Noisy Labels: Incorrect or inconsistent labels can severely impact the model’s ability to learn accurate patterns. For instance, in image classification, mislabeled images can confuse the model, leading to unreliable predictions. Regular audits, leveraging human-in-the-loop systems, or employing semi-supervised learning can help mitigate the impact of noisy labels and improve overall accuracy.
- Overfitting Risk: Overfitting occurs when the model memorizes the training data instead of learning generalizable patterns, making it perform poorly on unseen data. This is particularly common with complex models trained on small or unrepresentative datasets. Employing techniques like regularization (e.g., L1/L2 regularization), dropout, early stopping, and cross-validation can effectively combat overfitting, ensuring the model maintains a balance between training performance and generalization.
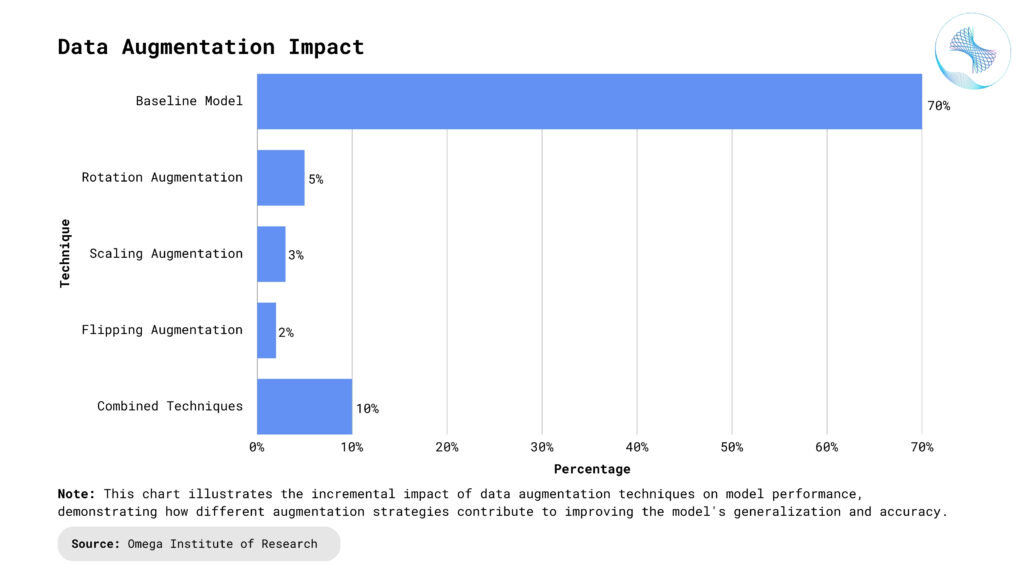
Validation Data: The Tuning Tool
Hyperparameter Tuning: Hyperparameters are critical settings that influence how a model learns, such as the learning rate, batch size, or number of hidden layers. Validation data provides essential feedback by showing how changes to hyperparameters affect results. For example, a learning rate that is too high may cause the model to diverge, while one that is too low can result in suboptimal learning. By systematically adjusting hyperparameters and monitoring validation performance, you can identify the optimal configuration for efficient learning.
Preventing Overfitting: Validation data plays a crucial role in preventing overfitting by highlighting how well the model generalizes to unseen data during training. Overfitting occurs when a model performs exceptionally well on training data but poorly on new data, indicating it has memorized patterns. Techniques like early stopping, where training halts when validation performance stops improving, are instrumental in mitigating overfitting. Using validation data to fine-tune regularization parameters, such as dropout rates or L2 penalties, ensures the model balances complexity and generalization.
Model Selection: When comparing multiple models or architectures, validation data serves as the benchmark for selecting the best-performing one. For instance, you might evaluate a decision tree, random forest, and neural network to determine which provides the highest accuracy or F1 score. Validation metrics ensure this decision is based on unbiased performance rather than overfitting to training data. The validation set also helps refine model configurations, such as selecting the depth of a tree or the number of layers in a neural network.
Independence: Validation data must remain entirely separate from training data to ensure unbiased evaluations. Overlapping data can lead to artificially inflated performance metrics, as the model may memorize examples rather than generalize. Ensuring independence allows the validation set to provide an honest assessment of the model’s performance. This separation is particularly important when evaluating models for critical applications, such as healthcare or finance, where unbiased assessments are essential for reliability.
Representativeness: The validation set should accurately reflect the distribution of real-world data to provide meaningful insights. For example, in a language translation model, including a mix of formal, casual, and technical texts ensures the model’s performance is evaluated across diverse contexts. If the validation set fails to represent the target data distribution, the model’s performance on real-world tasks may differ, leading to suboptimal deployment outcomes. A well-curated validation set ensures reliable feedback and alignment with real-world scenarios.
Test Data: The Final Exam
Unbiased Evaluation: The test data provides the ultimate measure of the model’s generalization ability, serving as the gold standard for assessing performance. Unlike validation data, which informs the training process, the test set is used only once to evaluate the final model. This ensures the results reflect how the model will perform on entirely new data in production. A well-designed test set provides an unbiased benchmark, offering insights into the model’s strengths and areas for improvement in real-world applications.
Real-World Simulation: Test data should closely mirror the conditions the model will face in its actual application, ensuring its relevance and reliability. For instance, in an e-commerce recommendation system, the test set might include user behavior data from different seasons, regions, or customer segments. By simulating real-world variations, the test set evaluates the model’s ability to adapt to dynamic scenarios. This approach ensures the model can handle unexpected changes and maintain performance consistency when deployed.
Single Use: Reusing the test set for multiple evaluations risks introducing bias, as the model may become tailored to the test data rather than generalizing well. To prevent this, the test set should be reserved for final evaluation only, ensuring that metrics reflect true performance. This practice maintains the integrity of the evaluation process and avoids overfitting to specific test examples. Additionally, having a separate test set ensures a clear distinction between training, validation, and final assessment phases.
Diverse Representation: A robust test set should include a wide range of scenarios to evaluate the model’s performance under varied conditions. For example, in autonomous vehicle systems, the test set might feature data from diverse weather conditions, traffic patterns, and road types. Including such variability ensures the model can handle edge cases and perform reliably across different environments. This diversity in the test set is crucial for building models that are not only accurate but also resilient in real-world applications.
Why Split Data?
Fair Evaluation: Splitting data into training, validation, and test sets is crucial for assessing a model’s true performance on unseen examples. This separation ensures that the evaluation reflects how the model will perform in real-world scenarios, providing a fair and unbiased measure of its capabilities. Without distinct splits, it’s challenging to determine whether the model has genuinely learned patterns or simply memorized the data. Proper data partitioning also highlights the importance of maintaining data independence throughout the development lifecycle, ensuring the model’s reliability.
Improved Generalization: Validation and test sets play a vital role in ensuring the model generalizes well to new, unseen data. For instance, a model trained to classify images of cats and dogs should not only work on the training images but also excel on new photos featuring pets in different settings, lighting, and poses. This process helps verify that the model captures underlying patterns rather than overfitting to specific examples. By validating generalization, you ensure the model’s utility across a wide range of real-world applications.
Error Detection: Data splits are instrumental in identifying common issues like overfitting, underfitting, or data leakage early in the development process. For example, if the model performs exceptionally well on training data but poorly on validation data, it signals overfitting or a mismatch in data distribution. Regular monitoring of performance across splits helps uncover these problems, enabling corrective actions such as refining the dataset, adjusting hyperparameters, or revising the model architecture. This proactive approach ensures a more robust and reliable final model.

Best Practices for Data Splitting
Typical Ratios: A common practice in data splitting is allocating 70-80% of data for training, 10-15% for validation, and 10-15% for testing. These ratios ensure a balanced approach to learning, tuning, and evaluation. However, depending on the dataset size and complexity, these percentages may vary. For smaller datasets, techniques like k-fold cross-validation can maximize the utility of limited data while maintaining robust and reliable evaluations. Larger datasets may allow for more flexibility, ensuring ample data for all phases without compromising performance.
Randomization: Shuffling the data before splitting is essential to ensure representative and unbiased subsets. For example, in a time-series dataset, failing to shuffle could result in the training set containing only older data and the test set containing newer data, leading to inaccurate evaluations. Randomization prevents patterns or biases in the data from skewing the model’s performance. It also ensures that the training, validation, and test sets reflect the overall data distribution, leading to fairer assessments and better generalization.
Stratification: In classification problems, stratification ensures that all classes are proportionally represented in each split, maintaining the integrity of the dataset’s distribution. For instance, if one class dominates the training set, the model may struggle to perform well on underrepresented classes. Stratified splitting prevents such issues by balancing class representation across all subsets. This approach is particularly important in imbalanced datasets, where ensuring proportionality helps the model learn effectively and generalize better to unseen data.
Avoid Data Leakage: Data leakage occurs when information from the test or validation set inadvertently influences the training process, leading to overly optimistic performance metrics. For instance, in a time-series forecast model, including future data points during training would invalidate the results. To avoid leakage, it’s crucial to ensure strict separation between the training, validation, and test sets. Implementing robust data handling practices, such as carefully preprocessing and splitting the data, helps maintain the integrity of the evaluation and ensures reliable model performance in real-world scenarios.
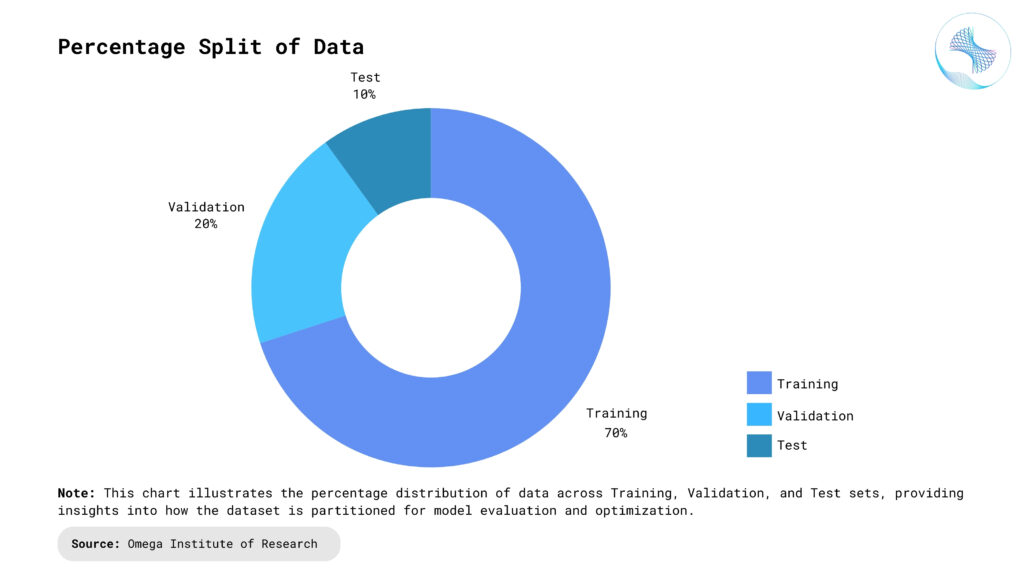
Common Pitfalls to Avoid
Data Leakage: Data leakage occurs when information from the test set inadvertently influences the training or validation process, leading to artificially inflated performance metrics. For example, including test set labels in feature engineering or preprocessing steps would make the model appear more accurate than it actually is in real-world scenarios. To avoid this, it’s crucial to ensure strict separation between the training, validation, and test sets. Data leakage can be subtle, so implementing careful data handling practices and regularly auditing the process can help maintain the integrity of model evaluation.
Imbalanced Splits: Allocating too little data for validation or testing can result in unreliable evaluations and skewed performance metrics. For instance, if the test set is too small, performance may not accurately reflect the model’s ability to generalize to unseen data. A balanced data split ensures that each subset has enough data to provide meaningful insights. Ensuring a proper distribution of data across training, validation, and test sets helps the model perform well across different phases, preventing misleading results from overly small subsets.
Ignoring Distribution Shifts: If the training, validation, and test sets come from different distributions, the model’s performance may degrade when deployed in real-world applications. This issue arises when the data used for training does not reflect the conditions the model will encounter in production. Ensuring consistency in data collection, preprocessing, and feature engineering across all splits is essential to avoid performance degradation. Regularly checking for distribution shifts and adjusting the model or data pipeline accordingly helps maintain the model’s robustness and reliability.
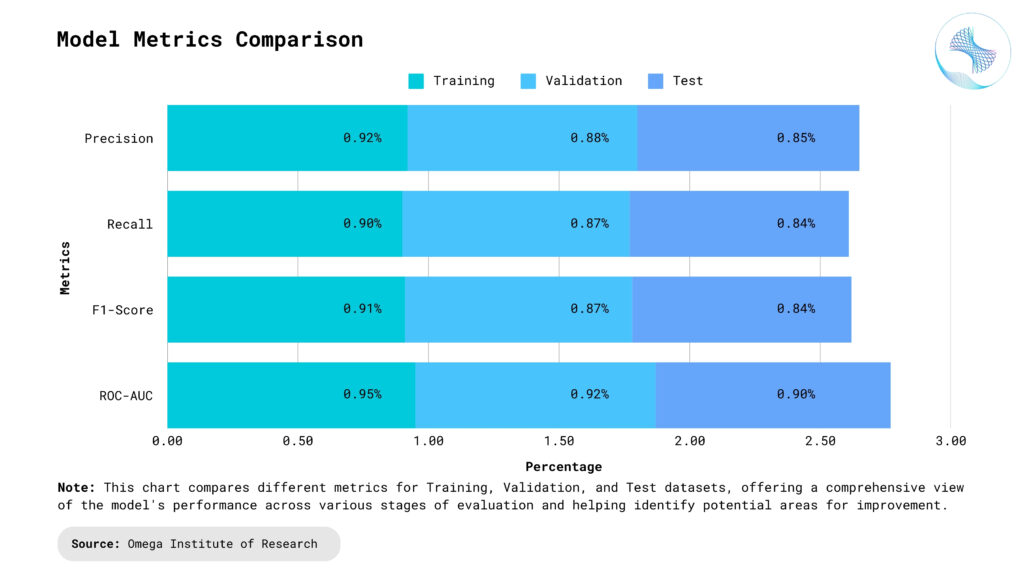
Conclusion
Training, validation, and test data sets are the cornerstone of effective machine learning workflows, serving as the foundation for developing models that generalize well to unseen data. By carefully managing these data sets and adhering to best practices, such as proper splitting, shuffling, and avoiding common pitfalls, you can build models that not only perform well during development but also excel in real-world applications. Mastering the art of data splitting is not just a technical necessity—it’s a strategic advantage in creating reliable and impactful machine learning solutions. This thoughtful approach ensures that models are robust, unbiased, and capable of handling the complexities of diverse, real-world scenarios, ultimately leading to more accurate and trustworthy outcomes.
- https://en.wikipedia.org/wiki/Training,_validation,_and_test_data_sets
- https://kili-technology.com/training-data/training-validation-and-test-sets-how-to-split-machine-learning-data
- https://www.applause.com/blog/training-data-validation-data-vs-test-data/
- https://mlu-explain.github.io/train-test-validation/
- https://medium.com/@eastgate/understanding-training-validation-and-testing-data-in-ml-c297e53d6096
Subscribe
Select topics and stay current with our latest insights
- Functions